The Architecture of Learning: Understanding Back-Propagation
In the world of modern AI, we often talk about “training” models as if it’s a magical process. We feed data into a system, and it eventually starts recognizing patterns. But for a long time, researchers were stuck on a specific problem: how do you teach the “middle” of a network to learn?
The answer came in 1986 with a landmark paper published in Nature titled “Learning representations by back-propagating errors” by David Rumelhart, Geoffrey Hinton, and Ronald Williams. This paper provided the blueprint for how almost every modern neural network—including the LLMs we use today—actually learns.
The Challenge: The “Hidden” Layer Problem
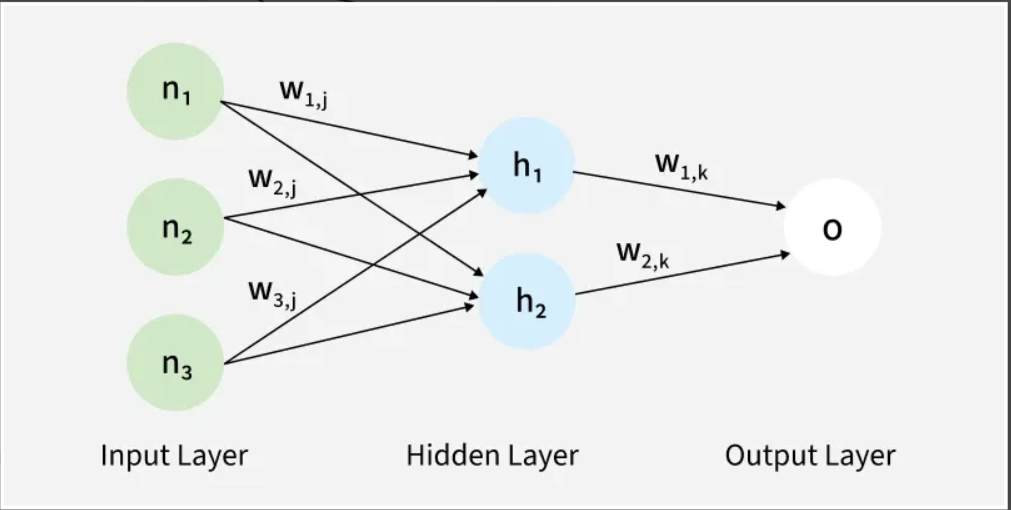
Before this paper, we could train very simple networks that had an input and an output. However, these “shallow” networks couldn’t solve complex problems. To handle real-world data, we needed hidden layers—layers between the input and output that could process abstract information.
The problem was “assignment of blame.” If a network gave the wrong answer, it was easy to see that the output was wrong. But how could you know which specific connection deep inside the hidden layers was responsible for that mistake? Without a way to “blame” and adjust those internal connections, the network couldn’t improve.
The Concept: A Two-Way Street
The authors proposed a elegant, two-phase process that allows a network to self-correct:
1. The Forward Pass (The Guess)
Data flows into the network at the bottom. It passes through the hidden layers, where various connections (weights) amplify or dampen the signal. Finally, it reaches the top and produces an output. At the start of training, because the connections are random, the network’s “guess” is almost always wrong.
2. The Backward Pass (The Correction)
This is the breakthrough. Instead of guessing how to fix the internal layers, the algorithm starts at the output, where we actually know the correct answer.
- It calculates the difference between the “guess” and the “truth.”
- It then sends that error signal backward through the network.
- As the error flows back, the algorithm calculates exactly how much each internal connection contributed to the mistake.
Learning Its Own Language
The most profound takeaway from the 1986 paper wasn’t just that the error could be sent backward, but that this process forced the network to create its own internal representations.
To reduce the error, the hidden units began to spontaneously organize themselves. In the paper’s experiments with family trees, the hidden units started to represent concepts like “generation” or “family branch”—even though the researchers never explicitly programmed those concepts. The network “invented” these categories simply because they were the most efficient way to get the right answer.
Why It Still Matters
Every time you interact with an AI today, you are interacting with the legacy of this paper. While we now have more layers and more complex math, the fundamental idea remains: forward to predict, backward to learn. It turned neural networks from static filters into dynamic systems capable of discovering the structure of the world on their own.
Reference
Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back-propagating errors. Nature, 323(6088), 533-536.